This summer, I worked on making automatic differentiation reliable and stable for the Enzyme project through Google Summer of Code. This post details the challenges I tackled and the solutions I implemented to bridge the gap between Rust's type system and Enzyme's requirements.
What is Enzyme AutoDiff? #
Enzyme is an LLVM-based automatic differentiation (AD) framework that can differentiate programs written in any language that compiles to LLVM IR. Unlike traditional AD tools that require special syntax or library calls, Enzyme works at the LLVM level, making it language-agnostic.
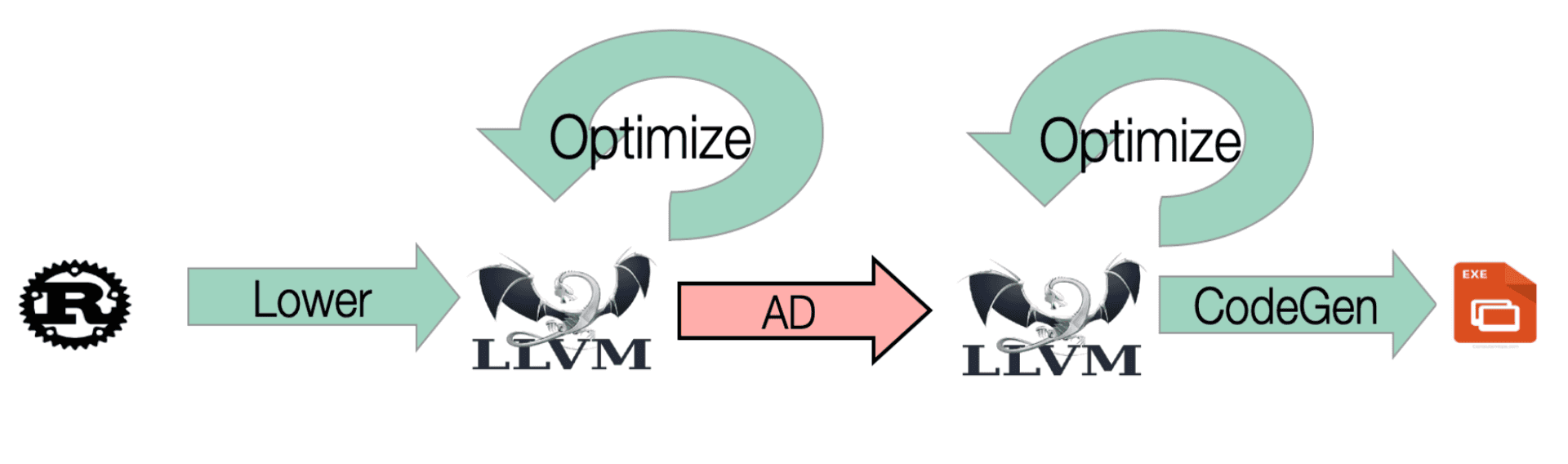
The performance challenges with Enzyme on Rust stem from a mismatch between how Rust represents types and what Enzyme needs to work effectively.
When Rust code gets compiled, it goes through several stages of transformation:
Rust's MIR (Mid-level IR): Contains type information including structs, enums, slices, and all the type system features that Rust provides.
LLVM-IR: By the time we reach LLVM's intermediate representation, most of this type information has been simplified or erased. Rust types become generic pointers (ptr), losing the Rust-specific details that Enzyme relies on.
Impact on Enzyme's Differentiation #
This type information loss creates several problems:
Correctness Issues: Enzyme depends on understanding the exact structure of data types to generate correct derivative code. Without type trees, some Rust constructs fail to compile entirely.
Compilation Overhead: The performance bottleneck comes from Enzyme's attempts to reconstruct this lost type information. The type analysis phase can increase compilation time as Enzyme tries to reverse-engineer what the original Rust types looked like from the simplified LLVM representation.
This is why a simple automatic differentiation that might take seconds in other languages can take minutes in Rust. The slowness isn't because the generated code is slow, but because the compilation process itself becomes a process of reconstructing lost type information.
My Contributions #
1. PrintTAFn Debug Flag #
Problem: Enzyme was printing type analysis for all functions, making debugging difficult when working on specific functions.
Solution: Added a new PrintTAFn flag that enables type analysis output for specific functions only.
This targeted debugging capability makes it much easier to identify and fix type analysis issues in specific functions without being overwhelmed by output from the entire codebase.
2. Comprehensive Test Suite for AutoDiff Module #
Problem: The autodiff module lacked proper testing, making it unclear whether issues were on the Enzyme side or LLVM side when functionality broke after updates.
Solution: Implemented a comprehensive run-make test suite for autodiff covering 22 different test cases.
- PR: #142444
- Coverage: Tests everything from primitive types to complex structures like
Vec and union - Benefit: Ensures we catch regressions immediately when updating autodiff components
This test suite was important because autodiff wasn't fully integrated into the CI pipeline, leaving maintainers uncertain about what was broken and what worked.
3. TypeTree Support #
This was the main contribution: implementing TypeTree support to solve the type information problem.
What are TypeTrees? #
TypeTrees are memory layout descriptors that tell Enzyme exactly how types are structured in memory, enabling efficient derivative computation.
Structure:
TypeTree(Vec<Type>)
Type {
offset: isize, // byte offset (-1 = everywhere)
size: usize, // size in bytes
kind: Kind, // Float, Integer, Pointer, etc.
child: TypeTree // nested structure
}
The Problem TypeTrees Solve #
Without explicit type information, Enzyme has to analyze the entire function to figure out how data is laid out in memory. This becomes a time-consuming guessing game, especially for complex Rust types that get compiled down to generic pointers.
TypeTrees solve this by telling Enzyme upfront: "this memory region contains floating-point data at these offsets, and this other region is just metadata that shouldn't be differentiated." Instead of reconstructing this information through expensive analysis, Enzyme can immediately generate the correct derivative code.
Before and After: The LLVM Perspective #
Without TypeTrees:
; Enzyme sees generic LLVM IR:
define float @distance(ptr %p1, ptr %p2) {
; Has to guess what these pointers point to
; Slow analysis of all memory operations
; May miss optimization opportunities
}
With TypeTrees:
define "enzyme_type"="{[]:Float@float}" float @distance(
ptr "enzyme_type"="{[]:Pointer}" %p1,
ptr "enzyme_type"="{[]:Pointer}" %p2
) {
; Enzyme knows exact type layout
; Can generate efficient derivative code directly
}
Key Concept: Offset -1 #
The special offset -1 means "this pattern applies everywhere" instead of listing each position separately. For example, an array [f32; 100] uses offset -1 rather than listing 100 separate offsets like 0, 4, 8, 12...396.
Implementation Details #
- Main PR: #144197
- Testing: Each TypeTree method includes comprehensive test coverage
- Safety: Added
NoTT flag to disable the feature if issues arise - Extended support: Added f128 support on Enzyme side (#2427)
- Documentation: Updated rustc-dev-guide for better understanding (#2385)
Impact and Future Work #
While we haven't yet completed comprehensive benchmarking of the performance improvements and stability gains from TypeTree implementation, the groundwork is in place. The combination of better debugging tools, comprehensive testing, and proper type information should improve Enzyme's performance on Rust code.
This work represents an important step toward making automatic differentiation in Rust as efficient and reliable as in other languages, opening up new possibilities for scientific computing and machine learning applications written in Rust.
Acknowledgments #
Special thanks to my mentors Johannes Doerfert (@jdoerfert), Manuel Drehwald (@ZuseZ4), and Kevin Sala (@kevinsala) for guidance on Enzyme integration and performance priorities. Special appreciation to Jubilee (@workingjubilee) for help whenever I was stuck. Thanks to LLVM Compiler Infrastructure and Google for supporting this work through GSoC.
Published
Subscribe for future blogs